CONTENTS
Evaluation metrics and a benchmark
We propose a modular evaluation metrics and a benchmark for large-scale federated learning. Firstly, we construct a suite of open-source non-IID dataset by providing three methods including partitioning of datasets randomly, partitioning dataset with digit labels, and redefining datasets’ labels with both main concepts and contexts of datasets, which are grounded inreal-world assumptions. In addition, we design a rigorous evaluation metrics including the number of network nodes, the size of datasets, the number of communication rounds, communication resources, etc. Finally, we provide an open-source benchmark data for large-scale federated learning research.
Framework
The Evaluation Metrics and Benchmark Paradigm is:
Non-IID Dataset Module
Requirements
requirements.txt
matplotlib==3.1.1
pandas==0.25.0
pyparsing==2.4.1.1
pyrsistent==0.15.3
python-dateutil==2.8.0
torch==1.2.0
torchvision==0.4.0
yaml
Environment: python3.6
pip3 install -r requirements.txt
Non-IID Formula Definition
Adding a standard to measure the degree of non independence and distribution of data. Using NI,

usage
step1: download datasets
step2: run NEI.py with datasets
step3: get results
Non-IID Dataset Generation
According to number of nodes, we split CIFAR10 dataset. We can customize the config.yaml configuration file. Set the split mode, randomly or by category. Set the number of nodes, the size of the data set for each node, and the number of each node category. In addition, we can also set the same distribution of data sets to increase the error dataset.
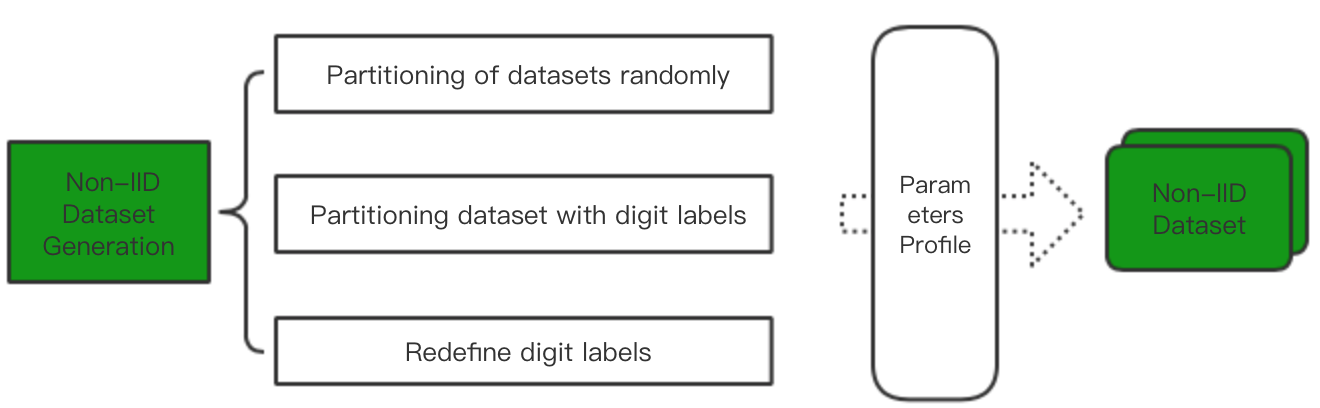
In this part, we use downloadData.py 、makeDataset.py and preprocess.py to generate non-IID datasets. More importantly, we provide a config file config.yaml for setting related parameters about non-IID datasets. We now work on MNIST and CIFAR10 datasets.
In config.yaml:
We will create non-IID dataset based on the number of nodes;
In config.yaml file: we will create non-IID dataset based on the number of nodes;
We will set node_num parameter which represents the number of dataset we want to generate. For example, we want 500 dataset with 500nodes. We will set node_num: 500.
# dataset
dataset_mode: MNIST/ CIFAR10
# node num Number of node (default n=10) one node corresponding to one dataset,
node_num: 4
# small dataset config
isaverage_dataset_size: false # if average splits dataset
# numpy.random.randint(10000, 20000 , 20)
#dataset_size_list: [18268, 16718, 10724, 12262, 17094, 14846, 17888, 14273, 13869,
## 18087, 19631, 15390, 14346, 12743, 11246, 18375, 15813, 18280,
## 12300, 12190]
dataset_size_list: [1822, 1000, 1200, 1300]
# split mode
split_mode: 0 # dataset split: randomSplit(0), splitByLabels(1)
# each node - label kind , sum must <= 10
# numpy.random.randint(0, 11, 20)
node_label_num: [ 4, 3, 2, 10]
isadd_label: false
add_label_rate: 0.1
isadd_error: false
add_error_rate: 0.01
We will generate n custom datasets.
In downloadData.py:
We can download differents datasets such as MNIST, CIFAR10.
In makeDataset.py:
In this part, we provide different methods for partitioning dataset.
- randomSplit: 1) no error dataset 2) add error dataset
- splitByLabel:
- just split dataset
- add other dataset, no error dataset
- add error dataset, no other dataset
- add both dataset
- redefineLabels
We will generate n custom datasets. On cifar10 files, every npy file consists of python’s List.
npy file: [[imgs, label], [imgs, label]...., [imgs, label]]
We can see the name of each npy file:
npy file name: split node index mode_dataset size_target label_the ratio of other label_the ratio of error dataset
In preprocess.py:
We will use readnpy method to read npy file
def readnpy(path):
# npy file: [[imgs, label], [imgs, label]...., [imgs, label]]
# when allow_pickle=True, matrix needs same size
np_array = np.load(path, allow_pickle=True)
imgs = []
label = []
for index in range(len(np_array)):
imgs.append(np_array[index][0])
label.append(np_array[index][1])
torch_dataset = Data.TensorDataset(torch.from_numpy(np.array(imgs)), torch.from_numpy(np.array(label)))
dataloader = Data.DataLoader(
torch_dataset,
batch_size=64,
shuffle=True
)
print(dataloader)
return dataloader
dataloader = readnpy("./xxxx/splitByLabelsWithNormalAndErrorDataset/SplitByLabels_2222_horseandMore_0.1_0.01.npy")
Evaluation Metrics
Data Nodes Number: In federated learning, it is an unavoidable learning process that multiple nodes participate in learning to get a global model.
The Communication Rounds: There is no doubt that the communication rounds of nodes play an important role in the performance of the model.
The Weight of Data Nodes: We need to recognizes the importance of specifying how the accuracy is weighted across nodes, e.g., whether every node is equally important, or every data node equally important (implying that the more data, the more important the node).
The Quality of Data Nodes: In this part, we research the influence of the same distributed data or the same data proportion in the total data and the wrong data proportion in the total data proportion on the performance of the model. We regard the above properties as the quality of data.
Benchmark